
Learnings from Aztec’s Proving Contest
If you are thinking about building on Gevulot, register a key to get access to Devnet for free proof generation and verification. Or fill out this form if you are interested in joining the network as a prover node operator.

Summary and outcome
In August, Aztec launched its first ProverNet, a permissioned testnet for decentralized proof outsourcing, incentivized through a contest held in September, with participation from around 15 teams.
Gevulot participated in both tracks:
Running the unmodified Aztec prover node software to generate proofs, and
Building custom integration with existing prover infrastructure.
The outcome for running Aztec’s prover node: Gevulot won in proving speed and tied in proven blocks. (All of the below teams submitted valid proofs for every block.)
Gevulot (avg time 419s)
Marlin (avg time 430s)
Lagrange (avg time 483s)
EmberStake (avg time 604s)
The outcome for building custom integration: Gevulot won the custom integration track.
In this blog post, we will reveal Gevulot’s journey related to Aztec’s first ProverNet, including challenges and lessons learned.
Aztec’s ProverNet
In early August, Aztec announced a Request for Integration for provers, with the purpose of testing decentralized proof generation. Projects interested in generating proofs for the Aztec Network were invited to participate in ProverNet, a permissioned testnet for provers, incentivized through a contest.
Gevulot has been actively involved in Aztec’s earlier community discussions around prover decentralization, proof-boost, and the RFC on the block-building process, and we were also committed to participating in the first ProverNet.
Two tracks with different focuses
For the contest, Aztec released a permissioned version of the network on top of an Ethereum mainnet fork. The whitelisted provers were processing blocks generated by a centralized sequencer, and the proofs were submitted back to the L1 fork.
The two tracks could be summarized as follows:
Running an Aztec prover node as is: the node automatically monitors unproven blocks, re-executes the transactions, internally orchestrates proof generation via the prover agents up to the final root proof, and submits it to L1. This track targeted all participants.
Building custom integration with existing infrastructure: this track focused on prover networks and proof markets to integrate the Aztec prover node with their infrastructure, through building custom interfaces between the orchestrator and the prover agents (the prover nodes of the prover network or marketplace), or building a custom implementation of the orchestrator interfacing with those prover agents.
Note: the Aztec prover node and orchestrator have small resource requirements, however, the prover agents are recommended to have 16-32 cores and 96-128 GB RAM each.
The proving process in Aztec’s ProverNet
To better understand the work the prover agents need to perform, let’s run through Aztec’s proving process.
Prover agents run Aztec’s ACVM to generate partial witnesses, and the Barretenberg cryptographic library for generating proofs. The proving process is comprised of multiple steps:
Once a prover agent picks up a job, the initial step is to convert the client-side proofs of each transaction into a Honk proof by running the Tube circuit.
Transactions may include public functions to be executed, requiring the Aztec Virtual Machine and Public Kernel circuits to be run.
Then the proofs for individual transactions are aggregated through a tree-like structure, via the Base, Merge, and Root Rollup circuits.
The final root proof is submitted by the prover node to the L1 fork.

*Source: https://hackmd.io/@aztec-network/prover-integration-guide
Pre-contest preparation and development
In the coming paragraphs, we will share details about our journey with regard to both tracks of the ProverNet contest. First, we will focus on pre-contest learnings, and afterward on the ones during the contest.
Building custom integration on Gevulot’s Devnet (Track #2)
In our journey, we started off focusing on the custom integration because the official ProverNet was not yet up and running.
As a preparation, we were setting up a local version of the network. Since Aztec is using a Docker image, the sandbox environment could be run in almost no time. We only had to provide an RPC to a local Ethereum L1. The Aztec sandbox was built to work with Anvil. You can find step-by-step instructions on how to create a forked L1 here.
The sandbox comprises the full stack with initial test accounts for easy development.

Spinning up a full node and a prover node separately
We also wanted to run a full node, the prover node, and the prover agent separately. The main difference between the sandbox and the full node is that in the latter case, the protocol contracts are not deployed, test accounts are not created, etc, and setting up the full node requires additional steps to make the local network usable. Here are the steps to run each component of the Aztec stack separately to set up a full, non-sandbox environment.
Run a full node:
docker run \
--rm -it --name aztec-full-node \
--link ethereum-network:rpc \
--publish 8080:8080 \
--env ETHEREUM_HOST=http://rpc:8545 \
--env SEQ_SKIP_SUBMIT_PROOFS=1 \
--env DEPLOY_AZTEC_CONTRACTS=true \
aztecprotocol/aztec:0.47.1 \
start --node --archiver --sequencer --prover --pxeNote: We applied SEQ_SKIP_SUBMIT_PROOFS=1, which is a temporary flag not to submit proofs so that the prover node would do it.
The Aztec RPC will become available at the host’s http://127.0.0.1:8080.
Deploy the protocol contracts:
docker exec -it aztec-full-node \
node --no-warnings /usr/src/yarn-project/aztec/dest/bin/index.js deploy-protocol-contractsNote: The protocol contracts are deployed to L2. The L1 rollup contracts can be deployed by applying DEPLOY_AZTEC_CONTRACTS.
Bootstrap the network:
docker exec -it aztec-full-node \
node --no-warnings /usr/src/yarn-project/aztec/dest/bin/index.js bootstrap-networkRun the prover node:
docker run \
--rm -it --name aztec-prover-node \
--link aztec-full-node:full-node \
--link ethereum-network:rpc \
--publish 8081:8080 \
--env AZTEC_NODE_URL=http://full-node:8080 \
--env LOG_LEVEL=verbose \
--env ETHEREUM_HOST=http://rpc:8545 \
--env PROVER_REAL_PROOFS=true \
aztecprotocol/aztec:0.47.1 \
start --prover-node --prover --archiverBuilding custom prover agent
When the contest was announced, Aztec also published a Prover Integration Guide, including details on possible custom builds to extend the prover node.
We started building a prover agent from scratch, that queries jobs from the proving queue using the JSON-RPC and calls Barretenberg’s CLI to generate the proof. When querying the RPC with Postman, the response was that the method provingJobSource_getProvingJob did not exist.
While analyzing the code, we found that the RPC is enabled when the prover node is started with the internal agent enabled. We were expecting the opposite: if no internal prover agent exists, then jobs are exposed via RPC.
As a workaround we increased the internal agent polling time, and called the RPC in the meantime, hoping to win the race condition. It indeed worked (see screenshot), and we were able to get some jobs. As a side note, a few days later the above RPC behavior was fixed by Aztec as well.

Mapping proving jobs with CLI calls
Next up, we wanted to find out how a proving job is mapped with the CLI call and decided to investigate all CLI calls with their inputs and outputs.
As mentioned earlier, the two main binaries used in the proving process were the ACVM which generates a partial witness based on input data, and the Barretenber (BB) prover. The CLI calls were debug-logged both for BB and ACVM. Here are some sample logs for both:
aztec:acvm-native [DEBUG] Calling ACVM with execute --working-directory /usr/src/yarn-project/acvm/tmp-fQ4uZY --bytecode bytecode --input-witness input_witness.toml --print --output-witness output-witnessaztec:bb-prover [DEBUG] BaseParityArtifact BB out - Executing BB with: prove_ultra_honk_output_all -o /usr/src/yarn-project/bb/tmp-zvUJQE -b /usr/src/yarn-project/bb/tmp-zvUJQE/BaseParityArtifact-bytecode -w /usr/src/yarn-project/bb/tmp-zvUJQE/partial-witness.gz -vWe wanted to capture the expected outputs but got an error when invoking both ACVM and BB. When looking at the Docker file we discovered that the binaries were built for x86_64-linux but at that time we were using an ARM-based machine.
# we don't build the bb binary for arm so this will be copied but won't be working on arm images
FROM --platform=linux/amd64 aztecprotocol/barretenberg-x86_64-linux-clang as barretenbergPersisting workdirs
By default, all workdirs were removed, but we wanted to capture them too. Since all CLI calls were wrapped with runInDirectory(), we simply removed the reference to the cleanup ( fs.rm() call) by patching the JS file:
sed -i '/fs.rm/d' ./foundation/dest/fs/run_in_dir.jsA week later Aztec also added BB_SKIP_CLEANUP to disable the cleanup, and afterwards also provided a template docker-compose.yml for running the local ProverNet. After running the official template and our cleanup patch for some time, we were able to capture all the logs and workdirs:
├── workdirs
│ ├── acvm
│ │ ├── tmp-0HH8Ef
│ │ ...
│ │ └── tmp-9LlqsX
│ └── bb
│ ├── tmp-0D0Omu
│ ...
│ └── tmp-9YCtCl
└── logs
├── aztec-provernet-aztec-block-watcher-1.json
├── aztec-provernet-aztec-bot-1.json
├── aztec-provernet-aztec-node-1.json
├── aztec-provernet-aztec-prover-1.json
├── aztec-provernet-aztec-prover-agent-1.json
└── aztec-provernet-ethereum-1.jsonExploring alternatives for custom prover agent
By polling jobs from the RPC queue, we lost time between event occurrence and polling. Therefore, we modified the existing prover agent to use a different ServerCircuitProver interface rather than the BarretenbergNativeProver. The idea was to implement the ServerCircuitProver interface in TypeScript:

With this modification, the job data was already parsed, but we had to customize the Aztec code and rebuild it.
It was difficult to build from sources due to the heavy host dependencies. We had issues with clang incompatibility and also had to install additional host dependencies (wasi-sdk-22 for ARM; Foundry built from sources, solhint npm package).
We had difficulties to compile BB on our machine, too, due to some issues that we reported (Issue#8341; Issue@8343). Therefore we made an aztec-packages fork and applied workarounds to disable the max_size_impl assert (2c3c5b20), and the ASM optimizations (cdb9f7b6).
With these, we were able to compile the BB binary but the full build process was unnecessarily long. As mentioned above, all we wanted was to add a custom implementation of the ServerCircuitProver interface, i.e. add a new typescript file, and make a one-line modification to use a different class. Due to the above complexities, we finally decided to take another route.
Injecting JS and patching
For sure we did not want to touch the build process, but still wanted to inject our custom implementation. To achieve this we prepared a simple TypeScript project with a dummy prover:

Then with the Docker multi-stage build, we injected the compiled JS and used sed to modify Aztec source. It worked very well and was also relatively easy compared to the earlier approach.
Deploying the Barretenberg prover on Gevulot’s Devnet
To give a bit of context, Gevulot’s v1 network uses Nanos VM as runtime environment, i.e. the program must be built as a unikernel. This is single-process only, with no fork support, the syscalls are limited, and there is no networking. Handling program input and output is done via gRPC transported over VSOCK. The next generation of our network, Firestarter, launching in about a week, already uses containers and Linux VM, but for the contest, we had to build our integration using Nanos unikernel images.
The BB integration, in a nutshell, was a complex task and required several workarounds.
Spawning external process for gunzip
The current setup spawns gunzip to read input bytecode, creating unnecessary dependencies as gunzip, jq, and base64 must be available on the host, and making it incompatible with single-process environments.
As a workaround, our alternative approach was to allow direct loading of already unpacked files, intending to unpack them before sending tasks to Gevulot.

Our recommendation to Aztec would be to reduce external dependencies by using libraries for data processing instead of spawning processes.
Downloading trusted setup data
The BB prover spawns the curl command to fetch the trusted setup data from Aztec Ceremony, which involves downloading several large files (up to 6.4 GB for G1 data). However, Gevulot’s Devnet does not support networking.
We implemented a caching mechanism to store these files locally ($HOME/.bb-crs), avoiding repeated downloads. Also, an additional grumpkin_size file was needed for Grumpkin data to specify the byte size of the G1 data file.

As a recommendation to Aztec, the get_file_size could be used dynamically to check file sizes, similar to the G1 data for Bn254. In addition, the network requirements with curl availability on the host should be documented.
C++ code integration with Gevulot
Barrettenberg is written in C++, while the Gevulot shim helper is written in Rust with FFI bindings (Foreign Function Interface). To deploy the BB prover on the network, we exposed BB’s main() as a library function and created a Gevulot-wrapper binary in Rust that links to this library. This allowed the Rust wrapper to call the underlying BB’s CLI via FFI, and we were able to deploy the prover to Gevulot successfully.
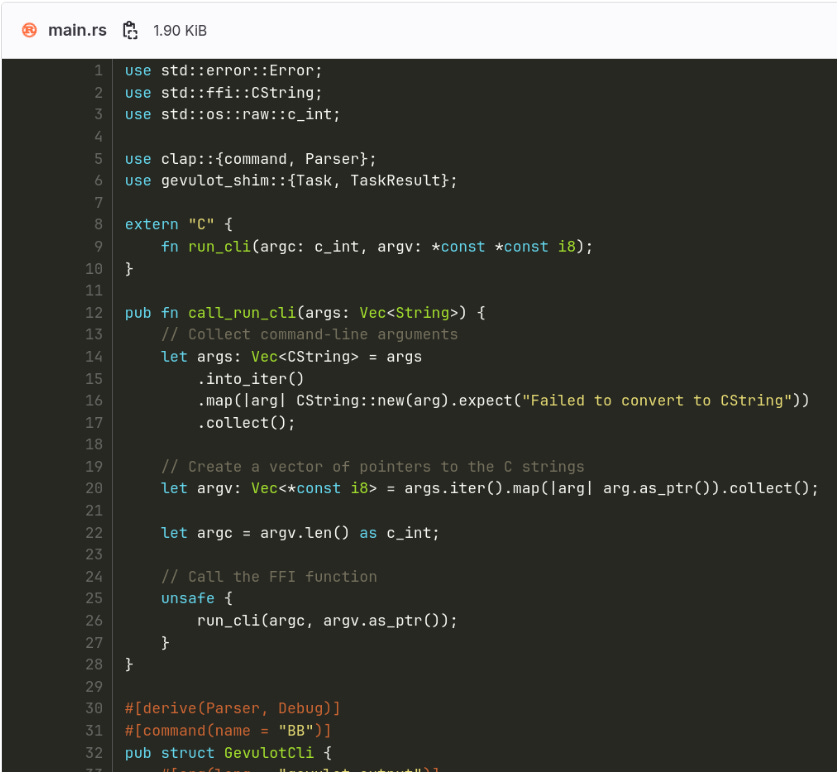
The entire prover deployment process, with a sample call and fetching results, is described in detail in the integration repository.
Dropping the idea of retrieving jobs from the queue via RPC
Aztec's initial suggestion was to implement a custom proving agent that retrieves jobs from a queue using RPC. Although the JSON jobs were accessible, it was unclear how to proceed with parsing them. The key challenges were 1. whether to use an existing NPM package with job types or implement parsing from scratch; 2. which functions should be called and to which input files should job types be mapped.
Substituting the BB binary with a wrapper
We did not want to modify the Aztec code but intended to replace the native prover with the Gevulot one. So we decided to build a wrapper that delegated tasks to the Gevulot network. We named our project coordinator2, though in hindsight, 'bb_remote' might have been more appropriate.
Our wrapper maintains the same interface as BB, and focuses on delegating three key proving commands:
prove_ultra_honk_output_all,
prove_tube,
avm_prove.
For other commands, we fall back to the native BB binary using FFI.
The main wrapper logic was:
Try parsing args according to the
coordinator2interface, potentially matching one of three proving commands and handling it in a dedicated way.In case of error, pass all args to FFI, so it will work exactly as native binary.
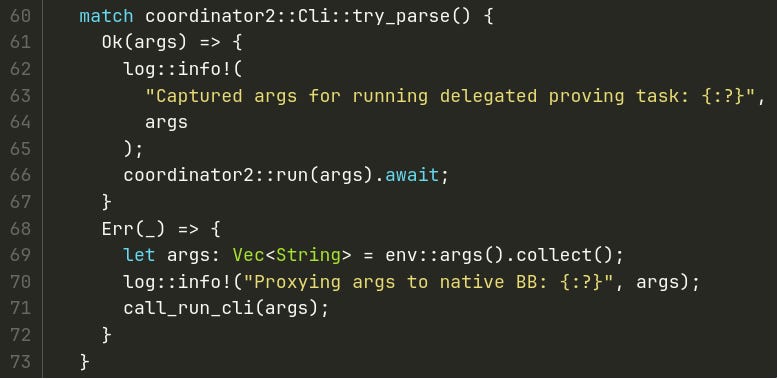
To handle the 'delegated' commands we needed a module for uploading files and a module for interacting with Gevulot.
Handling file storage
To handle file storage, we integrated with Google Cloud Storage using the gsutil crate that provided gsutil::cp::cmd() for uploading files.
By implementing fn upload_to_bucket(self, local_path: &Path, remote_name: &str) we were able to upload any local file to our bucket and get its public URL.
Interacting with Gevulot
We implemented functions to interact with Gevulot via RPC, including uploading tasks, waiting for completion, and downloading results.
Waiting for task was about querying the transaction tree, and looking for the first NodeHash. Here we also used a retry mechanism. Downloading the results included querying the transaction, extracting output URLs, and downloading them. Some fields were private in the output, so as a workaround we also had to do a serialization-deserialization round trip with a mirror-struct.

Delegating proving jobs
With all base components in place, we continued to implement handlers for the delegated proving commands: prove_ultra_honk_output_all, prove_tube, and avm_prove. The flow is similar for all of them, here are the steps for the prove_tube handler:
Collect all input paths.
Upload input files to a public server (GCS).
Build Gevulot task definition.
Construct Gevulot transaction.
Send transaction and allow for processing time.
Periodically poll for results and download output files when ready.
After some minor bug-fixing, the initial tests of the BB wrapper were successful and all proving jobs were running in Gevulot. The only thing left was to benchmark each job to estimate their resource needs and adjust delays for the first query, polling interval, and timeouts.
As mentioned at the beginning, we started off focusing on the custom integration. In the meantime, the configuration of the ProverNet was finished, and it was time for us to set up the unmodified Aztec stack and start testing the infrastructure to find the optimal setup.
Running the unmodified Aztec prover node (Track #1)
As mentioned, releasing the Aztec client in Docker containers made it very straightforward to spin up the prover node with the agents.
Before running the prover node, we had to fund our account in the L1 fork through the Aztec faucet. For this, we spawned the Aztec container and called the drip function.
Preparations and machines used
According to Aztec’s benchmarks, a prover node can run on a 2-core and 4GB RAM machine. For the prover agent though, it is recommended to have 16-32 cores with 96-128GB RAM. We used a ‘c3d-standard-30’ for the master node and four ‘c3d-standard-180’ machines for the agents. With regards to PROVER_AGENT_CONCURRENCY, we were able to run up to 10 agents on each ‘c3d-standard-180’ machine, more than that resulted in OOM.
For more insights on how to run the unmodified Aztec node in GCP, see our detailed instructions.
Challenges and learnings
While preparing for the contest, the Aztec team was still actively working on the ProverNet, and the branch was updated a few times. Following the updates, we had to pull the images again, verify the hash, and repeat requesting test ETH from the faucet. We found that if Aztec tracked changes with semantic versioning, this process could be easier.
What was also challenging is that there were no details available on config options such as max_pending_jobs in the prover node, or hardware_concurrency env used by the Barretenberg prover. We were running tests with different parameters to find the most optimal settings.
The contest
Block size and frequency during the contest
The contest was planned to run from 3 September, 3 PM UTC until the same time on 6 September. The initial parameters related to block production were:
Block frequency: new blocks published every ~4.5 minutes.
Block size: 4 transactions per block.
The goal was to increase block frequency to ~1 minute, and the block size to 8 transactions during the contest. Both of these changes meant that additional prover agents had to be spun up to be able to keep up with the chain, so we made preparations accordingly.
Running the unmodified Aztec prover node (track #1)
With the above GCP machines, we reached an average proving time of 419 seconds per block, which was the fastest among all participants.
Proving speed per circuit
Aztec provided information on circuit proving times on a 32-core machine with 128 GB RAM which served as a great benchmark.
At Gevulot, we were able to reach an average of ~35% improvement in proving times for most circuits when running the unmodified Aztec prover node. Some examples are:
Tube circuit: 4 minutes (Aztec) vs. 2 minutes and 28 sec (Gevulot),
Base rollup circuit: 2 minutes (Aztec) vs. 1 minute and 20 sec (Gevulot),
Root rollup circuit: 37 sec (Aztec) vs. 23 sec (Gevulot).
Managing increased block frequency
After two days, on 5 September, Aztec increased the block frequency to release new blocks ~ every minute, instead of every ~4.5 minutes. The block size, 4 transactions per block, remained unchanged.
To keep up with the chain, the increased block frequency required multiple prover agents. Our initial setup of 4 instances with 10 prover agents each was able to manage the increased workload, though the average proving time somewhat increased.
Preparing for increased transaction count
Aztec was also planning to increase the block size from 4 to 8 transactions per block. Let us remember that only proofs generated within a 20-minute time window were accepted during the contest. Since Tube proofs are generated for each transaction, and take 4 minutes each as per Aztec benchmarks, a block with 8 transactions released every minute can only be proven within the 20-minute time window if at all times a sufficient number of agents are available to pick up the incoming jobs and to do proving parallel.
We were preparing to spin up a couple of additional machines to make sure we could keep up with the chain, however, unexpectedly the ProverNet went down due to state corruption, as we learned later. The participating teams were waiting eagerly for news regarding the network restart. We were expecting a network restart to also require restarting our nodes, and we did not want to miss any blocks. However, despite several attempts, the network was never revived, and the 8-transaction blocks never got released. Aztec decided to cut the contest short and end the contest as is. The Aztec team selected a cut-off block before the state corruption and evaluated the teams’ performance up to that block.
The outcome of the generic Aztec node track
Four teams were able to submit a valid proof for every single block within the 20-minute time-out window, and this meant there was a tie in the number of proven blocks. But what about proving speed?
Gevulot came on top, with an average block-proving time of 419 seconds, followed by Marlin (430 sec), Lagrange (483 sec), and EmberStake (604 sec).
It was closer than anyone would have thought, with proving speed finally being the tiebreaker. Congratulations to all participating teams for the amazing work pulled off.
Custom integration with Gevulot’s Devnet (track #2)
Gevulot released its v1 network (Devnet) in March 2024. It includes the entire proving pipeline and has generated over 2 million proofs, hosting almost 400 prover programs. However, it has certain limitations: it does not have horizontal scaling implemented, and thus we could not parallelize the generation of Tube proofs. This means that while we were able to reach ~20-minute proving time, we did not have the chance to keep up with the chain. The next-gen network, Gevulot Firestarter, launching soon does not have this limitation, and will be able to keep up with the chain.
First proofs
On 4 September we successfully submitted 2 proofs to the L1 fork. The first one took 50 minutes to generate, while the second one took 1 hour and 10 minutes, both of which exceeded the given 20-minute timeout by far. But the fact that we were able to submit proofs to L1, proved that our integration was working as intended.
Fixing issues
We identified our two main bottlenecks:
Fetching the Aztec Ceremony data (over 2GB) in each task, instead of embedding it directly in the prover’s deployment files caused unnecessary network traffic, and delayed the task startup.
The Gevulot node’s RPC was too slow when it came to fetching task results: we got many timeouts and lost precious minutes trying to fetch results of already completed tasks.
The first bottleneck was easy to solve, but there was no solution for the second one in the current Gevulot Devnet.
Proof generation in 20 minutes
We were fighting against time, it was already the morning of 5 September, and block frequency had been increased already. Even though we fixed only the caching issue, it was time to test the performance.
The prover node was started at 11:56:07.436:
{"log":"2024-09-05T11:56:07.436Z aztec:prover-node [INFO] Started ProverNode\n","stream":"stderr","time":"2024-09-05T11:56:07.436308506Z"}The block proving job was started at 11:56:09.233:
{"log":"2024-09-05T11:56:09.233Z aztec:block-proving-job [INFO] Starting block proving job fromBlock=788 toBlock=788 uuid=99c96875-894a-4b3f-b3fe-7fc6042c9db4\n","stream":"stderr","time":"2024-09-05T11:56:09.233615462Z"}The proving job was finished at 12:16:09.328:
{"log":"2024-09-05T12:16:09.328Z aztec:block-proving-job [INFO] Finalised proof for block range fromBlock=788 toBlock=788 uuid=99c96875-894a-4b3f-b3fe-7fc6042c9db4\n","stream":"stderr","time":"2024-09-05T12:16:09.328410631Z"}The proof was submitted at the same time, and confirmed 10 seconds later:
{"log":"2024-09-05T12:16:09.328Z aztec:sequencer:publisher [INFO] SubmitProof size=15188 bytes\n","stream":"stderr","time":"2024-09-05T12:16:09.328718021Z"} {"log":"2024-09-05T12:16:20.190Z aztec:sequencer:publisher [INFO] Published proof to L1 rollup contract gasPrice=1000000007 gasUsed=215617 transactionHash=0x1ac97928cbc3bf5786c2544de64aacaa332179c0b4b43162a3f3eaf6249df24f calldataGas=173060 calldataSize=15428 eventName=proof-published-to-l1 blockNumber=0x0000000000000000000000000000000000000000000000000000000000000314\n","stream":"stderr","time":"2024-09-05T12:16:20.19043159Z"}We got the proof generated in almost exactly 20 minutes, a tiny bit above that, to be fair.
At this point, we were very optimistic about running it again with fine-tuned concurrency level and RPC timeout/retry settings, however, this was the point when the network suddenly went down. As mentioned earlier, after several attempts to bring the network back online, Aztec decided to end the contest one day earlier than planned.
We had no more opportunities to deliver further proofs using the custom integration, but in the end, we got it fully working on the current Devnet as well, despite all its limitations, which was quite a feat in itself.
The outcome of the custom integration track
When the winners were announced by Aztec, we were very pleased to learn that our custom integration came on top, and with this, Gevulot won the custom integration track.
What is Aztec building?
Aztec is building a privacy-focused zk-L2, launching as a decentralized network from day one. The team has been leading transparent community discussions through Requests for Proposals (RFPs) on several topics, including the Sequencer Selection RFP, Upgrade RFP, and Prover Coordination RFP, allowing anyone to submit design proposals, following which a Request for Comments (RFC) was issued on Aztec’s block production.
Regarding proof generation, Aztec chose to implement a protocol called Sidecar which facilitates out-of-protocol proving. To ensure decentralization, provers can join in a permissionless manner, be it a vertically integrated sequencer, a prover network, or a proof market. Prover coordination would eventually be based on proof-boost or similar that allows for smooth negotiation between sequencers and provers. The current ProverNet was the first one to test outsourced proof generation in Aztec.
What is Gevulot building?
Gevulot is building ZkCloud, the first universal proving infrastructure for ZK. It supports any proof system and allows users to generate proofs at a fraction of the cost, offering fast, decentralized, and cheap proving. With its protocol-level execution guarantees, ZkCloud makes proof outsourcing seamless.
Gevulot’s current v1 network, while permissioned, includes the entire proving pipeline: users can deploy any arbitrary proof system as a prover program, submit proof requests, and have proofs generated and verified, all free of charge. The permissioned version of the ZkCloud, a scalable and production-ready prover network called Firestarter is launching in about a week. It can scale to thousands of prover nodes and serve the heaviest proving tasks, including proving Ethereum L1.
Conclusions
Gevulot will continue to be actively involved in Aztec’s community discussions whether it be around prover decentralization, proof-boost, or block building in general. Building a decentralized network ourselves, we are committed to participating in the upcoming ProverNets, providing fast and reliable proof generation, and we are also dedicated to supporting the decentralization efforts of all rollups in any ecosystem.
———
About Us:
Gevulot is building ZkCloud, the first universal proving infrastructure for ZK. Generate ZK proofs for any proof system at a fraction of the cost. Fast, cheap, and decentralized.
Learn more about Gevulot:
Website | Docs | GitHub | Blog | X (Twitter) | Galxe Campaign | Telegram | Discord